Faisant suite à l’annonce par l’équipe de développement de Stability AI du lancement de son nouveau générateur de sons AI bien nommé Audio stable. Ce guide de présentation rapide approfondira un peu la technologie et les ensembles de données utilisés pour former le site Web de génération de sons IA qui peut créez non seulement des effets sonores mais aussi de la musique en quelques secondes.
Au sein des technologies d’intelligence artificielle, les modèles génératifs basés sur la diffusion ont fait des progrès significatifs dans l’amélioration de la qualité et de la contrôlabilité des images, vidéo et audio générés. Ces modèles, notamment modèles de diffusion latente, fonctionnent dans l’espace de codage latent d’un auto-encodeur pré-entraîné, offrant des améliorations de vitesse substantielles dans la formation et l’inférence des modèles de diffusion. Cependant, un défi courant lors de la génération d’audio à l’aide de modèles de diffusion est la sortie de taille fixe, ce qui peut poser des difficultés lors de la génération d’audio de différentes longueurs.
Générateur de sons IA
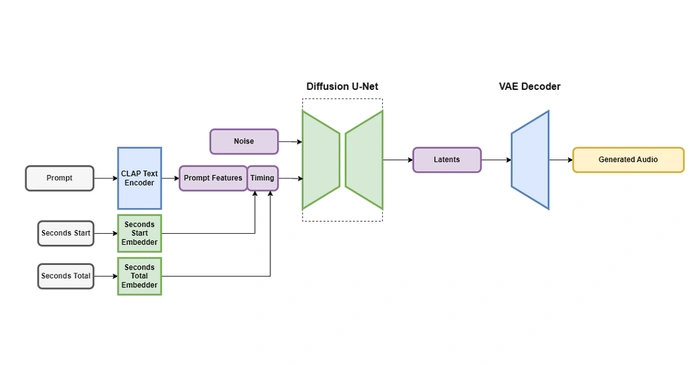
Pour résoudre ce problème, un nouveau architecture du modèle de diffusion latente, Audio stable, a été introduit. Ce modèle innovant est conditionné par les métadonnées du texte, la durée du fichier audio et l’heure de début, offrant ainsi un contrôle sur le contenu et la durée de l’audio généré. Contrairement à ses prédécesseurs, Stable Audio peut générer de l’audio d’une longueur spécifiée jusqu’à la taille de la fenêtre d’entraînement, surmontant ainsi les limitations d’une sortie de taille fixe.
L’une des principales caractéristiques de Stable Audio est son utilisation d’une représentation latente de l’audio fortement sous-échantillonnée, ce qui permet des temps d’inférence plus rapides. Ce modèle est capable de restituer 95 secondes d’audio stéréo à une fréquence d’échantillonnage de 44,1 kHz en moins d’une seconde sur un GPU NVIDIA A100démontrant sa rapidité et son efficacité impressionnantes.

Stabilité AI Audio stable
L’architecture de Stable Audio se compose d’un auto-encodeur variationnel (VAE), un encodeur de texte et un modèle de diffusion conditionnée basé sur U-Net. Le VAE joue un rôle crucial dans la compression de l’audio stéréo en un codage latent avec perte compressé, résistant au bruit et inversible, ce qui facilite une génération et une formation plus rapides. Le modèle est conditionné par des invites textuelles utilisant l’encodeur de texte figé d’un modèle CLAP formé à partir de zéro sur l’ensemble de données.
Autres articles qui pourraient vous intéresser sur le sujet de l’IA de stabilité :
Une autre caractéristique unique de Stable Audio est le calcul des intégrations temporelles pendant le temps d’entraînement. Cela permet à l’utilisateur de spécifier la longueur totale de l’audio de sortie pendant l’inférence, offrant ainsi un plus grand contrôle et une plus grande flexibilité dans la génération audio.
Le modèle de diffusion pour Stable Audio est un paramètre U-Net 907M basé sur le modèle utilisé dans Mousaï, témoignage de son architecture robuste et complexe. Pour entraîner le modèle Stable Audio, un ensemble de données de plus de 800 000 fichiers audio contenant de la musique, des effets sonores et des tiges d’instrument unique, ainsi que les métadonnées de texte correspondantes, ont été utilisés. Ce vaste ensemble de données souligne la gamme complète et diversifiée d’audio que Stable Audio peut générer.
Stable Audio est le produit de la recherche de pointe sur la génération audio menée par Harmonai, le laboratoire de recherche audio générative de Stability AI. Ce laboratoire est à la pointe de l’innovation dans le domaine de l’audio généré par l’IA, et Stable Audio témoigne de leur travail de pionnier.
Pour l’avenir, les prochaines versions de Harmonaï va inclure modèles open source basés sur Stable Audio et un code de formation pour la formation des modèles de génération audio. Ces développements à venir promettent de faire progresser encore le domaine de l’audio généré par l’IA, en offrant de nouvelles possibilités pour la création et la manipulation du son.
Stable Audio représente une avancée significative dans le domaine de l’audio généré par l’IA. En répondant aux limites de la sortie de taille fixe et en offrant un meilleur contrôle sur le contenu et la durée de l’audio généré, Stable Audio ouvre la voie à des modèles de génération audio plus sophistiqués et plus polyvalents. Essayez vous-même le nouveau générateur de sons AI sur le site officiel.
Classé sous : Guides, Top News
Dernières offres sur les gadgets geek
Divulgation: Certains de nos articles incluent des liens d’affiliation. Si vous achetez quelque chose via l’un de ces liens, Geeky Gadgets peut gagner une commission d’affiliation. Découvrez notre politique de divulgation.
Vous pouvez lire l’article original (en Angais) sur le blogwww.geeky-gadgets.com