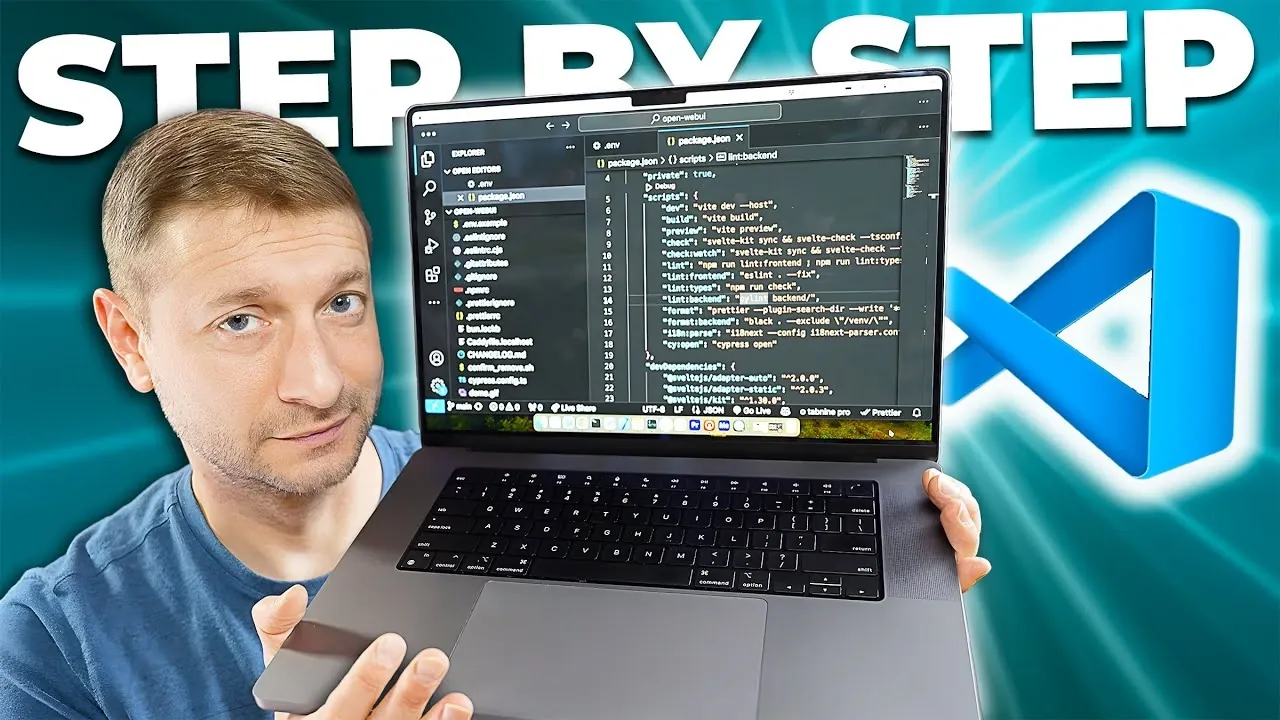
Et si l’avenir de l’IA n’était pas dans le cloud mais directement sur votre propre machine ? Alors que la demande d’IA localisée continue d’augmenter, deux outils :Lama.cpp et Ollama– sont devenus des pionniers dans ce domaine. Mais ils représentent deux visions très différentes de ce que peut être l’IA locale. D'un côté, Llama.cpp repousse les limites de personnalisation et évolutivitéoffrant aux développeurs un contrôle et des performances inégalés. D'un autre côté, Ollama simplifie le processus avec une interface conviviale pour les débutants mais sacrifie une partie de la puissance et de la flexibilité dont les utilisateurs avancés recherchent. La question n’est pas seulement de savoir quel outil est le meilleur, mais aussi celui qui correspond à votre vision de l’IA locale.
Dans cette description, Alex Ziskind vous explique comment Llama.cpp nouvelle interface Web redéfinit l'accessibilité et pourquoi il se concentre sur traitement parallèle en fait une option fantastique pour les applications exigeantes. Nous examinerons également la facilité d'utilisation d'Ollama et ses lacunes pour ceux qui recherchent des solutions hautes performances. Que vous soyez un développeur cherchant à pousser le matériel dans ses retranchements ou un nouveau venu en quête de simplicité, cette comparaison vous aidera à comprendre les forces et les faiblesses de chaque outil. Le choix entre Llama.cpp et Ollama ne concerne pas seulement les fonctionnalités, il concerne l'avenir de la façon dont nous interagissons avec l'IA selon nos propres conditions.
Llama.cpp et Ollama Présentation
TL;DR Points à retenir :
- La nouvelle interface Web de Llama.cpp améliore l'accessibilité et la convivialité, offrant des fonctionnalités telles que des statistiques détaillées sur les jetons, des informations sur les étapes de raisonnement, des paramètres personnalisables et la prise en charge du traitement parallèle pour améliorer la productivité.
- L'installation de Llama.cpp est flexible et bien documentée, prenant en charge diverses configurations matérielles, y compris des optimisations pour Apple Silicon et une compatibilité avec des formats de modèles tels que GGUF et Safe Tensors pour une intégration transparente.
- Llama.cpp surpasse Ollama en termes d'évolutivité et de concurrence, ce qui le rend idéal pour les charges de travail complexes et multithread, tandis que la simplicité et la facilité d'utilisation d'Ollama s'adressent aux débutants ou aux applications de base.
- Llama.cpp prend en charge diverses options de quantification (par exemple, modèles 8 bits et 4 bits) et l'intégration avec des modèles pré-entraînés à partir de plates-formes telles que Hugging Face, permettant une optimisation des performances sur mesure pour du matériel et des cas d'utilisation spécifiques.
- Grâce à sa polyvalence, son évolutivité et son engagement en faveur de la transformation locale, Lama.cpp offre un contrôle, une indépendance et une sécurité accrus, ce qui en fait un choix solide pour les développeurs et les organisations déployant des solutions d'IA à grande échelle.
L'interface Web de Llama.cpp : un bond en avant dans l'accessibilité
L'introduction d'une interface utilisateur (UI) basée sur le Web pour Llama.cpp représente une avancée majeure pour rendre les outils d'IA locaux plus accessibles et conviviaux. Cette nouvelle interface simplifie les interactions avec le modèle, offrant une gamme de fonctionnalités conçues pour améliorer la convivialité et l'efficacité :
- Statistiques détaillées des jetons : Obtenez des informations sur les performances et le comportement du modèle pendant le traitement.
- Informations sur l'étape de raisonnement : Comprendre comment le modèle traite et génère des réponses.
- Paramètres personnalisables : Ajustez les paramètres en fonction de tâches ou de flux de travail spécifiques.
L'une des caractéristiques les plus remarquables de cette interface est sa prise en charge du traitement parallèle. Cette fonctionnalité vous permet de gérer plusieurs conversations ou tâches programmatiques simultanément, ce qui la rend particulièrement utile pour les applications nécessitant une simultanéité élevée. En permettant des flux de travail plus fluides et en réduisant les goulots d'étranglement, l'interface Web de Llama.cpp améliore considérablement la productivité et l'efficacité opérationnelle.
Installation et configuration : rationalisées pour plus de flexibilité
La configuration de Llama.cpp nécessite la création de l'outil à partir des sources, un processus bien documenté et adaptable à diverses configurations matérielles. Pour les utilisateurs d'appareils Apple Silicon, des optimisations spécifiques sont disponibles pour maximiser les performances, garantissant ainsi une utilisation efficace des ressources matérielles.
Un aspect essentiel du processus de configuration implique la compréhension et l’utilisation des formats de modèle. Llama.cpp prend en charge des formats largement reconnus tels que GGUF et Safe Tensors, appréciés pour leur compatibilité et leur efficacité. Si vous envisagez d'utiliser des modèles pré-entraînés, leur conversion dans ces formats est essentielle pour une intégration transparente et des performances optimales. Cette flexibilité de configuration garantit que Llama.cpp peut être personnalisé pour répondre à diverses exigences, des développeurs individuels aux déploiements à grande échelle.
Guide de configuration de l'IA locale pour Apple Silicon et macOS
Libérez plus de potentiel dans IA locale en lisant les articles précédents que nous avons écrits.
Optimisation des performances et du matériel
Llama.cpp excelle dans l'utilisation des capacités matérielles pour offrir des performances supérieures. En utilisant des GPU, notamment Apple Silicon et d’autres matériels avancés, il permet une génération de jetons plus rapide et une réactivité améliorée. Cela en fait un excellent choix pour les développeurs travaillant sur des tâches gourmandes en ressources ou sur des applications nécessitant un traitement en temps réel.
En revanche, Ollama propose un processus d'installation plus simple et une interface utilisateur plus basique, ce qui le rend attrayant pour les débutants ou ceux ayant des besoins simples. Cependant, ses capacités de concurrence limitées peuvent constituer un inconvénient dans les scénarios exigeant un traitement parallèle ou un débit élevé. Cette distinction met en évidence l'avantage de Llama.cpp dans la gestion de charges de travail complexes et multithread, ce qui en fait une solution plus robuste pour les applications exigeantes.
Llama.cpp vs Ollama : comparer les forces
Bien que Llama.cpp et Ollama soient tous deux conçus pour le déploiement local de l'IA, leurs approches et leurs atouts diffèrent considérablement :
- Ollama : Se concentre sur la facilité d'utilisation, offrant une interface intuitive idéale pour les débutants ou les utilisateurs ayant des exigences simples. Cependant, son manque de fonctionnalités avancées et son évolutivité limitée peuvent limiter son utilité pour des projets plus complexes.
- Lama.cpp : Donne la priorité à l’évolutivité et à la personnalisation, ce qui le rend adapté aux développeurs et aux organisations disposant d’applications à forte demande. Sa capacité à exécuter plusieurs instances sur des ports distincts et sa prise en charge du traitement parallèle garantissent une plus grande flexibilité et efficacité.
Il y a de plus en plus de spéculations selon lesquelles Ollama pourrait passer à des solutions basées sur le cloud, ce qui pourrait limiter son attrait pour les utilisateurs recherchant un déploiement d'IA entièrement local. En revanche, Llama.cpp reste attaché au traitement local, offrant aux utilisateurs plus de contrôle, d’indépendance et de sécurité.
Sélection et quantification de modèles : optimisation des performances
Choisir le bon modèle et le bon niveau de quantification est crucial pour optimiser les performances. Llama.cpp prend en charge diverses options de quantification, notamment des modèles 8 bits et 4 bits, qui réduisent les besoins en ressources tout en conservant la précision. Cette flexibilité vous permet d'adapter l'outil à votre matériel et à votre cas d'utilisation spécifiques, garantissant ainsi un fonctionnement efficace sans compromettre la qualité.
Des plates-formes telles que Hugging Face offrent un accès facile aux modèles pré-entraînés, qui peuvent être intégrés de manière transparente à Llama.cpp. En expérimentant différentes configurations et niveaux de quantification, vous pouvez affiner l'outil pour obtenir les meilleurs résultats adaptés à vos besoins particuliers, que vous travailliez sur un projet à petite échelle ou sur une application de grande envergure gourmande en ressources.
Flexibilité et évolutivité : l'avantage concurrentiel
L'une des plus grandes forces de Llama.cpp réside dans sa polyvalence. Il est compatible avec une large gamme de systèmes, des Mac aux clusters Nvidia et AMD, ce qui le rend adapté au déploiement dans divers environnements. Cette adaptabilité garantit que vous pouvez utiliser l'outil quelle que soit votre configuration matérielle, offrant un niveau de flexibilité inégalé par de nombreuses autres solutions d'IA locales.
Pour les développeurs cherchant à maximiser le débit, Llama.cpp prend en charge l'exécution simultanée de plusieurs instances. En attribuant chaque instance à un port distinct, vous pouvez gérer des volumes de requêtes plus élevés sans compromettre les performances. Cette évolutivité fait de Llama.cpp un choix idéal pour les organisations et les développeurs souhaitant déployer des solutions d'IA à grande échelle.
Faire le bon choix pour l’IA locale
Les avancées de Llama.cpp, en particulier sa nouvelle interface Web et ses capacités de traitement améliorées, le positionnent comme un outil puissant pour le déploiement local de l'IA. L'accent mis sur la flexibilité, l'évolutivité et l'optimisation matérielle le distingue d'Ollama, qui, bien que convivial, n'a pas le même niveau de personnalisation et de performances.
Pour les développeurs et les organisations privilégiant le contrôle, l'indépendance et les hautes performances, Llama.cpp propose une solution complète. Son engagement en faveur du traitement local garantit que vous pouvez conserver un contrôle total sur vos déploiements d'IA, ce qui en fait un choix fiable et efficace pour un large éventail d'applications. Que vous soyez un développeur chevronné ou que vous exploriez l'IA locale pour la première fois, Llama.cpp fournit les outils et fonctionnalités nécessaires pour réussir dans ce domaine en évolution rapide.
Crédit média : Alex Ziskind
Classé sous : IA, Guides
Dernières offres sur les gadgets geek
Divulgation: Certains de nos articles incluent des liens d’affiliation. Si vous achetez quelque chose via l'un de ces liens, Geeky Gadgets peut gagner une commission d'affiliation. Découvrez notre politique de divulgation.
Vous pouvez lire l’article original (en Angais) sur le {site|blog}www.geeky-gadgets.com