
Le développement de modèles de grande langue (LLMS) entre dans une phase centrale avec l'émergence d'architectures basées sur la diffusion. Ces modèles, menés par des laboratoires de création à travers son nouveau système de mercure, présentant un défi important à la domination de longue date des systèmes à base de transformateurs. Mercure introduit une nouvelle approche qui promet Vitesses de génération de jetons plus rapides tout en conservant des niveaux de performance comparables aux modèles existants. Cette innovation a le potentiel de remodeler la façon dont l'intelligence artificielle gère le texte, l'image et la génération de vidéos, ouvrant la voie à des applications multimodales plus avancées qui pourraient redéfinir le paysage de l'IA.
«Le mercure est jusqu'à 10 fois plus rapide que les LLMs optimisés par la vitesse frontalière. Nos modèles fonctionnent à plus de 1000 jetons / sec sur NVIDIA H100S, une vitesse auparavant possible à l'aide de puces personnalisées. La famille Mercury de modèles de diffusion en grande langue (DLLMS), une nouvelle génération de LLM qui poussent la frontière de la génération de texte rapide et de haute qualité. «
Contrairement aux transformateurs, qui génèrent du texte un jeton à la fois, Mercury fait un saut audacieux en produisant des jetons en parallèle, réduisant considérablement les temps de réponse. Le résultat? Jusqu'à 10 fois plus de vitesses de génération plus rapides sans compromettre la qualité. Mais il ne s'agit pas seulement de la vitesse – il s'agit de débloquer de nouvelles possibilités pour l'IA, des applications en temps réel aux capacités multimodales comme la génération de texte, d'images et même de vidéos. Si vous vous êtes déjà demandé à quoi pourrait ressembler l'avenir de l'IA, vous êtes dans une balade passionnante.
Mercure Diffusion LLM
TL; Dr Key à retenir:
- LLMS basés sur la diffusion, comme Mercure des laboratoires de créationintroduisez une nouvelle architecture qui génère des jetons en parallèle, offrant un traitement plus rapide par rapport aux modèles traditionnels basés sur les transformateurs.
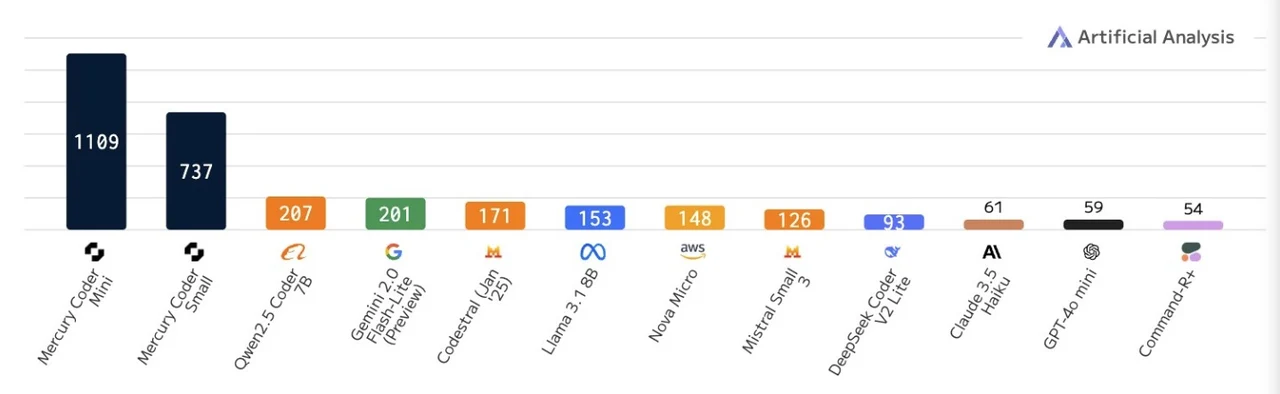
- Le mercure atteint jusqu'à 1 000 jetons par seconde, ce qui le rend 10 fois plus rapide que les modèles de transformateurs optimisés, sans compromettre la qualité de sortie, et est adapté à des tâches axées sur le codage.
- L'approche basée sur la diffusion de Mercury permet des capacités multimodales, y compris le texte, l'image et la génération de vidéos, en le positionnant comme un outil polyvalent pour des applications créatives et complexes de résolution de problèmes.
- Malgré sa vitesse et son potentiel, le mercure fait face à des défis tels que la manipulation des invites complexes et ses plafonds d'utilisation limités, mettant en évidence les zones pour un raffinement et une évolutivité supplémentaires.
- L'essor des LLM basés sur la diffusion signale un changement dans la recherche sur l'IA, le mercure ouvrant la voie et soulevant des questions sur l'avenir des architectures dominées par les transformateurs.
Comprendre les LLM basées sur la diffusion
Les LLM basées sur la diffusion représentent un changement fondamental dans la façon dont la langue est générée. Contrairement aux transformateurs, qui reposent sur une modélisation autorégressive séquentielle pour générer des jetons un à la fois, les modèles de diffusion fonctionnent en produisant des jetons en parallèle. Cette approche est inspirée par les processus de diffusion utilisés dans la génération d'images et de vidéo, où le bruit est supprimé de manière progressive pour créer des sorties cohérentes. En adoptant cette stratégie de génération de jetons parallèles, les LLM basées sur la diffusion visent à surmonter les défis de latence associés au traitement séquentiel. Le résultat est une solution plus rapide et potentiellement plus évolutive pour générer des sorties de haute qualité, ce qui rend ces modèles particulièrement attrayants pour les applications nécessitant des performances en temps réel.
Mercure: un modèle redéfinissant la vitesse et l'efficacité
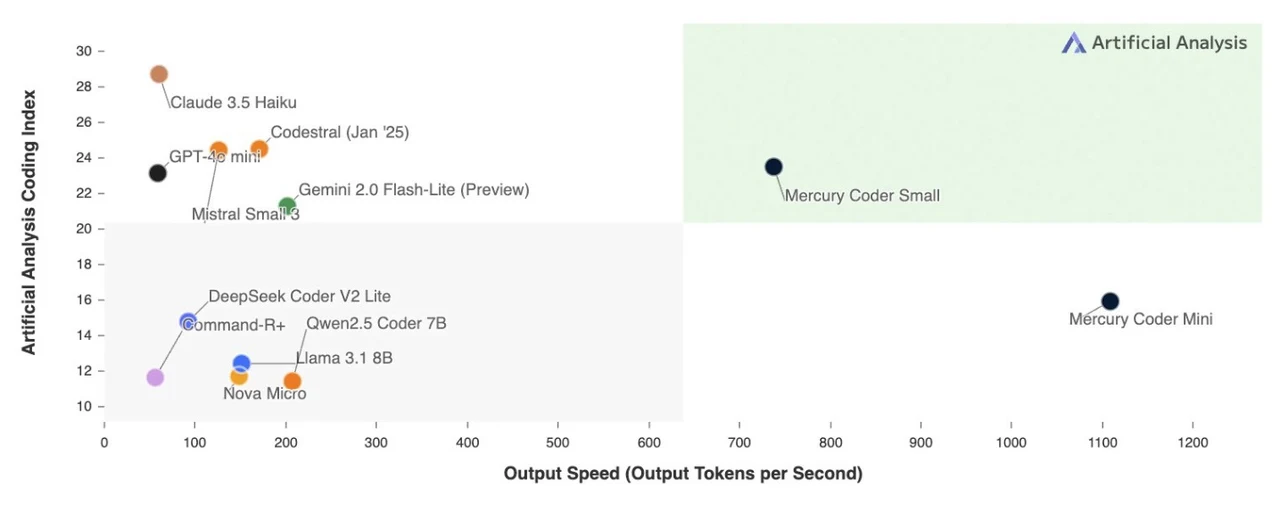
Le modèle Mercury des laboratoires de création a établi une nouvelle norme dans la technologie LLM. Capable de générer jusqu'à 1 000 jetons par seconde Sur le matériel NVIDIA standard, Mercury serait jusqu'à 10 fois plus rapide que même les modèles basés sur les transformateurs les plus optimisés par la vitesse. Ce saut de performance remarquable est obtenu sans compromettre la qualité des résultats générés, faisant du mercure une option attrayante pour les tâches qui exigent un traitement rapide. Actuellement, Mercury est disponible en deux versions spécialisées –Mercure coder mini et Mercury Coder Small– Toot adapté pour répondre aux besoins des développeurs travaillant sur des projets axés sur le codage. Ces versions mettent en évidence la polyvalence de Mercury et son potentiel à répondre aux applications de niche tout en maintenant ses forces fondamentales.
Les LLM de diffusion sont là! Est-ce la fin des transformateurs

Parcourez plus de ressources ci-dessous à partir de notre contenu approfondi couvrant plus de zones sur les modèles de grande langue.
Comment le mercure s'accumule contre les transformateurs
Le mercure a subi une analyse comparative rigoureuse contre les principaux modèles basés sur les transformateurs, notamment la lampe de poche Gemini 2.0, le GPT 40 Mini et les modèles ouverts comme Quin 2.0 et Deep Coder V2. Alors que ses performances globales s'alignent étroitement avec des modèles de transformateurs plus petits, Mercury génération de jetons parallèles lui donne un avantage distinct de vitesse. Cette capacité le rend particulièrement bien adapté aux applications nécessitant des réponses en temps réel ou un traitement de données à grande échelle, où l'efficacité et la vitesse sont essentielles. En répondant à ces besoins spécifiques, le mercure se positionne comme une alternative convaincante aux systèmes traditionnels basés sur les transformateurs, en particulier dans les scénarios où la réduction de latence est une priorité.
Applications et potentiel plus large
L'architecture basée sur la diffusion du mercure étend son utilité bien au-delà de la génération de texte. Sa capacité à générer images et vidéos Le positionne comme un outil polyvalent pour les industries explorant les applications créatives et multimédias. Cette capacité multimodale ouvre de nouvelles possibilités pour des secteurs tels que le divertissement, la publicité et la création de contenu, où la demande de visuels générés par AI-générée de haute qualité augmente. De plus, les capacités de raisonnement améliorées de Mercury et les flux de travail agentiques en font un candidat solide pour s'attaquer Tâches complexes de résolution de problèmescomme le codage avancé, l'analyse des données et les processus de prise de décision. Le mécanisme de génération de jetons parallèle améliore encore son efficacité, permettant des solutions plus rapides dans un large éventail de cas d'utilisation, des chatbots du service client aux systèmes de génération de contenu à grande échelle.
Défis et limitations actuelles
Malgré sa promesse, Mercure n'est pas sans défis. Les premières versions du modèle ont montré des difficultés à manipuler invites très complexes ou ambiguësqui met en évidence les domaines où un raffinement supplémentaire est nécessaire. De plus, l'utilisation actuelle est plafonnée à 10 demandes par heureune limitation qui pourrait entraver son adoption dans des environnements à forte demande. Ces contraintes soulignent la nécessité d'un développement et d'une optimisation continus pour débloquer pleinement le potentiel des LLM basées sur la diffusion. S'attaquer à ces premières limites sera crucial pour que le mercure d'atteindre une adoption plus large et de rivaliser efficacement avec les systèmes basés sur les transformateurs établis.
L'avenir des LLM basés sur la diffusion
Inception Labs propose des plans ambitieux pour étendre la portée de Mercury en l'intégrant dans les API, permettant aux développeurs d'incorporer de manière transparente ses capacités dans leurs flux de travail. Cette intégration pourrait accélérer l'innovation dans les applications LLM, favorisant le développement de systèmes d'IA plus efficaces et polyvalents. Le succès du mercure soulève également des questions importantes sur l'avenir de la conception LLM, avec des modèles basés sur la diffusion émergeant comme un Alternative viable au paradigme du transformateur. Alors que ces modèles continuent de mûrir, ils peuvent inspirer une vague de nouvelles architectures qui hiérarchisent la vitesse, l'évolutivité et les capacités multimodales.
Explorer d'autres architectures expérimentales
Bien que le mercure mène la charge dans les LLM basées sur la diffusion, ce n'est pas la seule architecture expérimentale en cours de développement. Les modèles de fondation liquide de liquide (LFM) représentent une autre tentative d'aller au-delà des transformateurs. Cependant, les premiers résultats indiquent que les LFM n'ont pas encore correspondu aux performances ou à l'efficacité de Mercure. Ces efforts reflètent un intérêt croissant pour la diversification des architectures LLM pour répondre aux limites des modèles existants. L'exploration d'approches alternatives, telles que les LFM et les systèmes basés sur la diffusion, signale un changement plus large dans la recherche sur l'IA, soulignant la nécessité d'innovation pour surmonter les contraintes des conceptions traditionnelles basées sur les transformateurs.
Façonner le chapitre suivant de l'IA
L'avènement des LLM basés sur la diffusion marque une étape importante dans l'évolution de l'intelligence artificielle. Mercure, avec son génération de jetons parallèles et les capacités multimodales, remet en question la domination des systèmes basés sur les transformateurs en offrant une alternative plus rapide et plus polyvalente. Bien que encore à ses débuts, cette innovation a le potentiel de remodeler l'avenir de l'IA, ce qui stimule les progrès dans le texte, l'image et la génération de vidéos. Alors que les modèles basés sur la diffusion continuent d'évoluer, ils pourraient bien définir le chapitre suivant dans le développement de modèles de langues, repoussant les limites de ce que l'IA peut réaliser sur un large éventail d'applications.
Crédit médiatique: Ingénierie rapide
Filed Under: AI, News News, Top News
Dernières offres de gadgets geek
Divulgation: Certains de nos articles incluent des liens d'affiliation. Si vous achetez quelque chose via l'un de ces liens, les gadgets geek peuvent gagner une commission d'affiliation. Découvrez notre politique de divulgation.
Vous pouvez lire l’article original (en Angais) sur le {site|blog}www.geeky-gadgets.com