
AWS S3 est le service de stockage cloud d’Amazon, vous permettant de stocker des fichiers individuels en tant qu’objets dans un compartiment. Vous pouvez télécharger des fichiers à partir de la ligne de commande sur votre serveur Linux, ou même synchroniser des répertoires entiers avec S3.
Si vous souhaitez simplement partager des fichiers entre des instances EC2, vous pouvez utiliser un Volume EFS et montez-le directement sur plusieurs serveurs, en supprimant complètement le « cloud ». Mais vous ne devriez pas l’utiliser pour tout, car c’est beaucoup plus cher que S3, même si l’accès peu fréquent est activé.
Limiter l’accès S3 à un utilisateur IAM
Votre serveur n’a probablement pas besoin d’un accès root complet à votre compte AWS. Par conséquent, avant d’effectuer tout type de synchronisation de fichiers, vous devez créer un nouvel utilisateur IAM que votre serveur pourra utiliser. Avec un utilisateur IAM, vous pouvez limiter votre serveur à la gestion uniquement de vos compartiments S3.
Du Console de gestion IAM, créez un nouvel utilisateur et activez « Accès par programmation ».
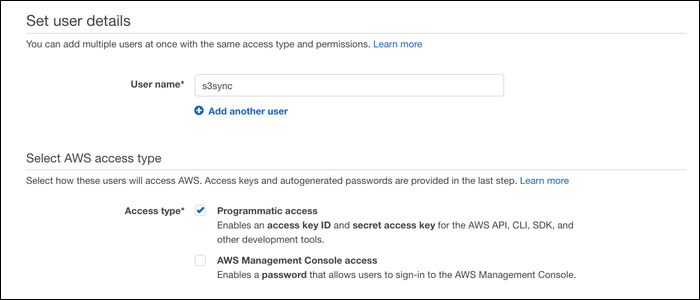
Vous serez invité à choisir les autorisations pour cet utilisateur. Créez un nouveau groupe et attribuez-lui l’autorisation « AmazonS3FullAccess ».
Après cela, vous recevrez une clé d’accès et une clé secrète. Notez-les; vous en aurez besoin pour authentifier votre serveur.
Vous pouvez également attribuer manuellement des autorisations S3 plus détaillées, telles que l’autorisation d’utiliser un compartiment spécifique ou uniquement de télécharger des fichiers, mais limiter l’accès à S3 uniquement devrait convenir dans la plupart des cas.
Synchronisation de fichiers avec s3cmd
s3cmd est un utilitaire conçu pour faciliter le travail avec S3 à partir de la ligne de commande. Il ne fait pas partie de l’AWS CLI, vous devrez donc l’installer manuellement à partir du gestionnaire de packages de votre distribution. Pour les systèmes basés sur Debian comme Ubuntu, ce serait :
sudo apt-get install s3cmd
Une fois que s3cmd est installé, vous devrez le lier à l’utilisateur IAM que vous avez créé pour gérer S3. Exécutez la configuration avec :
s3cmd --configure
Il vous sera demandé la clé d’accès et la clé secrète que la console de gestion IAM vous a fournies. Collez-les ici. Il existe quelques options supplémentaires, telles que la modification des points de terminaison pour S3 ou l’activation du chiffrement, mais vous pouvez les laisser toutes par défaut et sélectionner simplement « Y » à la fin pour enregistrer la configuration.
Pour télécharger un fichier, utilisez :
s3cmd put file s3://bucket
Remplacez « bucket » par le nom de votre bucket. Pour récupérer ces fichiers, exécutez :
s3cmd get s3://bucket/remotefile localfile
Et, si vous souhaitez synchroniser sur tout un répertoire, exécutez :
s3cmd sync directory s3://bucket/
Cela copiera l’intégralité du répertoire dans un dossier dans S3. La prochaine fois que vous l’exécuterez, il ne copiera que les fichiers qui ont été modifiés depuis sa dernière exécution. Il ne supprimera aucun fichier à moins que vous ne l’exécutiez avec le --delete-removed option.
s3cmd sync ne s’exécutera pas automatiquement, donc si vous souhaitez garder ce répertoire régulièrement mis à jour, vous devrez exécuter cette commande régulièrement. Vous pouvez automatiser cela avec cron; Ouvrez votre crontab avec crontab -e, et ajoutez cette commande pour terminer :
0 0 * * * s3cmd sync directory s3://bucket >/dev/null 2>&1
Cela synchronisera « répertoire » avec « seau » une fois par jour. D’ailleurs, si crontab -e t’a coincé vim, vous pouvez changer l’éditeur de texte par défaut avec export VISUAL=nano;, ou celui que vous préférez.
s3cmd a beaucoup de sous-commandes; vous pouvez copier entre les buckets avec cp, déplacez les fichiers avec mv, et même créer et supprimer des buckets à partir de la ligne de commande avec mb et rb, respectivement. Utiliser s3cmd -h pour une liste complète.
Une autre option : AWS CLI
Au-delà s3cmd, il existe quelques autres options de ligne de commande pour synchroniser des fichiers avec S3. AWS fournit ses propres outils avec l’AWS CLI. Vous aurez besoin de Python 3+ et pouvez installer la CLI à partir de pip3 avec:
pip3 install awscli --upgrade --user
Cela installera le aws commande, que vous pouvez utiliser pour interagir avec les services AWS. Vous devrez le configurer de la même manière que s3cmd, ce que vous pouvez faire avec :
aws configure
Il vous sera demandé de saisir la clé d’accès et la clé secrète de votre utilisateur IAM.
La syntaxe de l’AWS CLI est similaire à s3cmd. Pour télécharger un fichier, utilisez :
aws s3 cp file s3://bucket
Pour synchroniser un dossier entier, utilisez :
aws s3 sync folder s3://bucket
Vous pouvez copier et même synchroniser entre les compartiments avec les mêmes commandes. Vous pouvez utiliser aws help pour une liste complète des commandes, ou lisez le référence de commande sur leur site internet.
Sauvegardes complètes : Restic, Duplicity
Si vous souhaitez effectuer des sauvegardes volumineuses, vous pouvez utiliser un autre outil plutôt qu’un simple utilitaire de synchronisation. Lorsque vous synchronisez avec S3 avec s3cmd ou l’AWS CLI, toutes les modifications que vous avez apportées écraseront les fichiers actuels. Parce que le principal souci du stockage de fichiers dans le cloud n’est généralement pas panne de lecteur, mais suppression accidentelle sans accès à l’historique des révisions, c’est un problème.
AWS prend en charge gestion des versions de fichiers, ce qui résout quelque peu ce problème, mais vous pouvez toujours utiliser un programme de sauvegarde plus puissant pour le gérer vous-même, surtout si vous effectuez des sauvegardes complètes du lecteur.
Duplicité est un utilitaire simple qui sauvegarde les fichiers sous forme de volumes TAR chiffrés. La première archive est une sauvegarde complète, puis toutes les archives suivantes sont incrémentielles, ne stockant que les modifications apportées depuis la dernière archive.
C’est très efficace, mais la restauration à partir d’une sauvegarde est moins efficace, car le processus de restauration devra suivre la chaîne de modifications pour arriver à l’état final des données. Reste résout ce problème en stockant les données dans des blocs chiffrés dédupliqués et conserve un instantané de chaque version pour la restauration. De cette façon, l’état actuel des fichiers est facilement référençable et chaque révision est toujours accessible.
Les deux outils peuvent être configurés pour fonctionner avec AWS S3, ainsi qu’avec plusieurs autres fournisseurs de stockage. Alternativement, si vous souhaitez simplement sauvegarder des instances EC2 basées sur EBS, vous pouvez utiliser instantanés EBS incrémentiels, même si cela coûte plus cher que de sauvegarder manuellement sur S3.
Vous pouvez lire l’article original (en Angais) sur le blogwww.cloudsavvyit.com